In Week 1 (extraction) and Week 2 (embeddings + KMeans in BigQuery ML) we laid the groundwork. This week I built a Python BERTopic stage whose IDs stay stable across runs by mapping BERTopic’s internal clusters to stable topic IDs in BigQuery. I use Google Gemini again to generate nice labels for the extracted topic clusters.
This week we explore BERTopic + stable topic IDs (via an ID registry):
- Train a BERTopic model in Python (UMAP + HDBSCAN).
- Map BERTopic’s internal clusters (model_version, internal_topic_id)
- Ensure topic IDs remain consistent across retraining (no more ID jumps).
- Join human-readable labels and persist results into
video_topicsfor analysis. - Inspect results in Looker Studio and reflect on limitations.
Table of Contents
- Model storage in GCS (+ generous upload timeout)
- Backfill missing embeddings in BigQuery
- Build & train BERTopic (UMAP + HDBSCAN)
- CLI modes: TRAIN vs INFERENCE
- Daily inference: transform embeddings → topics
- Stable IDs via a registry +
dim_topicsbootstrap - Write daily video topics idempotently
- Better cluster labels with LLM
- Early Results & Charts
- Limitations & Next Steps
Below I show how main.py grew from a tiny scaffold to the final stable-ID pipeline — one step at a time.
1) Model storage in GCS (+ generous upload timeout)
For storing the model I chose google cloud storage and will download it before every inference.
def _parse_gs_uri(gcs_uri: str) -> tuple[str, str]:
if not gcs_uri.startswith("gs://"):
raise ValueError(f"Expected gs:// URI, got: {gcs_uri}")
without = gcs_uri[len("gs://"):]
bucket, _, prefix = without.partition("/")
return bucket, prefix.strip("/")
def download_model_from_gcs(gcs_uri: str, project_id: Optional[str]) -> str:
bucket, prefix = _parse_gs_uri(gcs_uri)
client_kwargs = {"project": project_id} if project_id else {}
gcs = storage.Client(**client_kwargs)
bkt = gcs.bucket(bucket)
tmpdir = pathlib.Path(tempfile.mkdtemp(prefix="bertopic_model_"))
local_file = tmpdir / os.path.basename(prefix)
bkt.blob(prefix).download_to_filename(str(local_file))
return str(local_file)
def upload_model_to_gcs(local_model_file: str, gcs_uri: str, project_id: Optional[str]):
bucket, prefix = _parse_gs_uri(gcs_uri)
client_kwargs = {"project": project_id} if project_id else {}
gcs = storage.Client(**client_kwargs)
bkt = gcs.bucket(bucket)
b = bkt.blob(prefix)
b.upload_from_filename(local_model_file, timeout=600)This will be used later by train_model() and load_model().
2) Backfill missing embeddings in BigQuery
Since I could not ensure that every transcript had embeddings already - I used the following helper to make sure that for the batch date everything has an embedding. It's executed before inference for the batch date.
def generate_missing_embeddings_for_data(bq: bigquery.Client, project: str, dataset: str, emb_table: str, batch_date: str, embedding_model: str, transcripts_table: str, transcripts_cleaned_table: str):
sql = f"""
INSERT INTO `{project}.{dataset}.{emb_table}` (
video_youtube_id, text, text_clean, emb, batch_date
)
SELECT
ge.video_youtube_id,
t.text AS text,
ge.content AS text_clean,
ge.ml_generate_embedding_result AS emb,
DATE(t.published_at) AS batch_date
FROM ML.GENERATE_EMBEDDING(
MODEL `{project}.{embedding_model}`,
(
SELECT
t.video_youtube_id,
s.text_clean AS content
FROM `{project}.{dataset}.{transcripts_table}` t
JOIN `{project}.{dataset}.{transcripts_cleaned_table}` s
USING (video_youtube_id)
LEFT JOIN `{project}.{dataset}.{emb_table}` ve
ON ve.video_youtube_id = t.video_youtube_id
WHERE DATE(s.published_at) = DATE(@d)
AND ve.video_youtube_id IS NULL
),
STRUCT(TRUE AS flatten_json_output)
) AS ge
LEFT JOIN `{project}.{dataset}.{transcripts_table}` t
ON t.video_youtube_id = ge.video_youtube_id
;
"""
job = bq.query(sql, job_config=bigquery.QueryJobConfig(
query_parameters=[bigquery.ScalarQueryParameter("d", "DATE", batch_date)]
))
return job.result()This writes embeddings only when missing for batch_date. The batch_date (UTC, date-typed) equals DATE(published_at) of the video on inference day.
3) Build & train BERTopic (UMAP + HDBSCAN)
The train_model uses build_bertopic to create the BERTopic instance and finally uploads the file via upload_model_to_gcs for later usage.
import umap, hdbscan
import numpy as np
from bertopic import BERTopic
import pathlib, tempfile
def build_bertopic(umap_neighbors, umap_components, min_cluster_size, min_samples, top_n_words) -> BERTopic:
umap_model = umap.UMAP(
n_neighbors=umap_neighbors, n_components=umap_components,
min_dist=0.0, metric="cosine", random_state=42
)
hdbscan_model = hdbscan.HDBSCAN(
min_cluster_size=min_cluster_size, min_samples=min_samples,
metric="euclidean", cluster_selection_method="eom", prediction_data=True
)
return BERTopic(
umap_model=umap_model, hdbscan_model=hdbscan_model,
top_n_words=top_n_words, calculate_probabilities=True,
language="multilingual", verbose=True, nr_topics=None
)
def train_model(project_id, model_gcs_path, bq, dataset, emb_table,
lookback_days, min_docs, umap_neighbors, umap_components, min_cluster_size, min_samples, top_n_words):
train_df = read_embeddings_lookback(bq, project_id, dataset, emb_table, lookback_days)
if train_df.empty or len(train_df) < min_docs:
raise RuntimeError(f"Not enough docs to train initial model (have {len(train_df)}, need >= {min_docs}).")
texts = train_df["text"].tolist()
embs = np.vstack(train_df["emb"].apply(lambda a: np.array(a, dtype=np.float32)).to_numpy())
topic_model = build_bertopic(umap_neighbors, umap_components, min_cluster_size, min_samples, top_n_words)
topic_model.fit(texts, embeddings=embs)
tmp = pathlib.Path(tempfile.mkdtemp(prefix="bertopic_save_")) / "model.pkl"
topic_model.save(str(tmp))
upload_model_to_gcs(str(tmp), model_gcs_path, project_id)
return topic_model4) CLI modes: TRAIN vs INFERENCE
To separate responsibilities, the job supports two modes: TRAIN and INFERENCE. The environment
variable JOB_MODE and will run the train_model only if it is set to TRAIN.
PROJECT_ID = required("PROJECT_ID")
BQ_DATASET = os.getenv("BQ_DATASET", "topicwatchdog")
EMB_TABLE = os.getenv("EMB_TABLE", "video_embeddings")
VIDEO_TOPICS_TABLE = os.getenv("VIDEO_TOPICS_TABLE", "video_topics")
DIM_TOPICS_TABLE = os.getenv("DIM_TOPICS_TABLE", "dim_topics")
TOPIC_REGISTRY_TABLE = os.getenv("TOPIC_REGISTRY_TABLE", "topic_registry")
MODEL_VERSION = required("MODEL_VERSION")
MODEL_GCS_BASE_PATH = required("MODEL_GCS_BASE_PATH")
MODEL_GCS_PATH = f"{MODEL_GCS_BASE_PATH}/model_{MODEL_VERSION}.pkl"
BATCH_DATE = os.getenv("BATCH_DATE")
JOB_MODE = os.getenv("JOB_MODE", "INFERENCE")
EMBEDDING_MODEL = os.getenv("EMBEDDING_MODEL", "text_embedding")
TRANSCRIPTS_TABLE = os.getenv("TRANSCRIPTS_TABLE", "transcripts")
TRANSCRIPTS_CLEANED_TABLE = os.getenv("TRANSCRIPTS_CLEANED_TABLE", "transcripts_cleaned")
# Initial-train knobs
LOOKBACK_DAYS = as_int("INIT_TRAIN_LOOKBACK_DAYS", 30)
MIN_DOCS = as_int("INIT_MIN_DOCS", 200)
UMAP_N_NEIGHBORS = as_int("UMAP_N_NEIGHBORS", 15)
UMAP_N_COMPONENTS = as_int("UMAP_N_COMPONENTS", 5)
MIN_CLUSTER_SIZE = as_int("MIN_CLUSTER_SIZE", 15)
MIN_SAMPLES = as_int("MIN_SAMPLES", 5)
TOP_N_WORDS = as_int("TOP_N_WORDS", 10)
bq = bq_client(PROJECT_ID)
if JOB_MODE.upper() == "TRAIN":
# Load or initial-train the model
topic_model = train_model(
project_id=PROJECT_ID,
model_gcs_path=MODEL_GCS_PATH,
bq=bq,
dataset=BQ_DATASET,
emb_table=EMB_TABLE,
lookback_days=LOOKBACK_DAYS,
min_docs=MIN_DOCS,
umap_neighbors=UMAP_N_NEIGHBORS,
umap_components=UMAP_N_COMPONENTS,
min_cluster_size=MIN_CLUSTER_SIZE,
min_samples=MIN_SAMPLES,
top_n_words=TOP_N_WORDS,
)
return And if it's set to INFERENCE I will load this model instead and call generate_missing_embeddings_for_data:
topic_model = load_model(
project_id=PROJECT_ID,
model_gcs_path=MODEL_GCS_PATH,
)
topic_info = topic_model.get_topic_info()
track("calculateTopics", {
"batchDate": BATCH_DATE,
"modelVersion": MODEL_VERSION,
"count": len(topic_info)
})
print(f"[INFO] Model {MODEL_VERSION} knows {len(topic_info)} topics")
generate_missing_embeddings_for_data(bq, PROJECT_ID, BQ_DATASET, EMB_TABLE, BATCH_DATE, EMBEDDING_MODEL, TRANSCRIPTS_TABLE, TRANSCRIPTS_CLEANED_TABLE);5) — Daily inference: transform embeddings → topics
Now let's fetch all the embeddings for the batch date from big query with the new function read_video_embeddings_for_date
def read_video_embeddings_for_date(bq: bigquery.Client, project: str, dataset: str, emb_table: str, batch_date: str) -> pd.DataFrame:
sql = f"""
SELECT video_youtube_id, text, emb, batch_date
FROM `{project}.{dataset}.{emb_table}`
WHERE batch_date = DATE(@d)
"""
job = bq.query(sql, job_config=bigquery.QueryJobConfig(
query_parameters=[bigquery.ScalarQueryParameter("d", "DATE", batch_date)]
))
return job.result().to_dataframe(progress_bar_type=None)We call it and transform these to topics by using topic_model.transform:
df = read_video_embeddings_for_date(bq, PROJECT_ID, BQ_DATASET, EMB_TABLE, BATCH_DATE)
if df.empty:
print(f"[INFO] No embeddings for {BATCH_DATE}. Exiting.")
return
texts = df["text"].tolist()
embs = np.vstack(df["emb"].apply(lambda a: np.array(a, dtype=np.float32)).to_numpy())
topics, probs = topic_model.transform(texts, embeddings=embs)
outlier_rate = (np.array(topics) == -1).mean()
print(f"[INFO] Outlier-Rate for {BATCH_DATE}: {outlier_rate:.2%}")
df["internal_topic_id"] = [int(t) for t in topics]
df["confidence"] = [float(p) if p is not None else None for p in probs.max(axis=1)]
df["batch_date"] = pd.to_datetime(BATCH_DATE).date()It was helpful to show the Outlier-Rate, which indicates that I should retrain the model.
6) Stable IDs via a registry + dim_topics bootstrap
# Registry & dim_topics bootstrap/mapping
registry = load_topic_registry(bq, PROJECT_ID, BQ_DATASET, TOPIC_REGISTRY_TABLE, MODEL_VERSION)
known = set(registry.keys())
seen = set(df["internal_topic_id"].unique().tolist())
new_internal = sorted(list(seen - known))
next_id_start = get_max_topic_id(bq, PROJECT_ID, BQ_DATASET, DIM_TOPICS_TABLE) + 1
# Labels/keywords and centroids for new internal topics
topic_labels: Dict[int, str] = {}
topic_keywords: Dict[int, List[str]] = {}
for internal_id in new_internal:
if internal_id == -1:
topic_labels[internal_id] = "OUTLIER"
topic_keywords[internal_id] = []
else:
top_words = topic_model.get_topic(internal_id) or []
kws = [w for (w, _ctfidf) in top_words][:TOP_N_WORDS]
topic_keywords[internal_id] = kws
topic_labels[internal_id] = ", ".join(kws[:4]) if kws else f"topic_{internal_id}"
# Centroids from this batch (good enough for bootstrap)
centroids: Dict[int, List[float]] = {}
for internal_id in new_internal:
mask = df["internal_topic_id"] == internal_id
if mask.any():
c = embs[mask].mean(axis=0)
centroids[internal_id] = [float(x) for x in c.tolist()]
else:
centroids[internal_id] = []
new_map_rows = []
for i, internal_id in enumerate(new_internal):
stable_id = next_id_start + i if internal_id != -1 else -1
confs = df.loc[df["internal_topic_id"] == internal_id, "confidence"]
new_map_rows.append({
"internal_topic_id": internal_id,
"topic_id": stable_id,
"confidence_min": float(confs.min()) if len(confs) else None,
"confidence_mean": float(confs.mean()) if len(confs) else None
})
if new_map_rows:
upsert_new_registry_and_dim_topics(
bq=bq,
project=PROJECT_ID,
dataset=BQ_DATASET,
registry_table=TOPIC_REGISTRY_TABLE,
dim_topics_table=DIM_TOPICS_TABLE,
model_version=MODEL_VERSION,
new_mappings=new_map_rows,
topic_labels=topic_labels,
topic_keywords=topic_keywords,
batch_centroids=centroids
)
registry = load_topic_registry(bq, PROJECT_ID, BQ_DATASET, TOPIC_REGISTRY_TABLE, MODEL_VERSION)
df["topic_id"] = df["internal_topic_id"].apply(lambda t: registry.get(int(t), -1))7) Write daily video topics idempotently
To have video_topics use somewhat "friendly" label and topics, I pulled the label + keywords from dim_topics table
and set topic + description on it by using their label and keywords.
# Join readable labels/keywords
label_map, keywords_map = {}, {}
for r in bq.query(f"""
SELECT topic_id, label, keywords
FROM `{PROJECT_ID}.{BQ_DATASET}.{DIM_TOPICS_TABLE}`
WHERE active_to IS NULL
""").result():
label_map[int(r["topic_id"])] = r["label"]
keywords_map[int(r["topic_id"])] = r["keywords"]
df["topic"] = df["topic_id"].map(lambda t: label_map.get(int(t), "UNKNOWN"))
df["description"] = df["topic_id"].map(lambda t: ", ".join(keywords_map.get(int(t), []) or []))
# video_topics (snippet_id = video id; no timestamp on whole-video embedding)
df["topic_timestamp"] = None
out = df[["video_youtube_id", "topic_id", "topic", "description", "confidence", "batch_date"]].copy()
upsert_new_video_topics(bq, PROJECT_ID, BQ_DATASET, VIDEO_TOPICS_TABLE, out)BERTopic’s internal cluster IDs can drift across retrains. The registry (model_version, internal_topic_id → topic_id) assigns monotonic stable IDs when a new internal ID appears. Old IDs are never reused. Labels/keywords live in dim_topics and can evolve without breaking historical facts.
8) Better cluster labels with LLM
Like last week I used the gemini model again to generate nice topic description based on some examples.
-- make sure all labels are empty
UPDATE topicwatchdog.topic_registry SET topic_label = NULL WHERE true;
-- fetch some clusters examples as input to gemini model
CREATE TEMP TABLE _cluster_examples AS
SELECT
vt.topic_id,
ARRAY_AGG(text_clean ORDER BY dv.views_count DESC LIMIT 50) AS examples,
COUNT(*) AS n
FROM `topicwatchdog.video_topics` vt
LEFT JOIN topicwatchdog.topic_registry tr ON vt.topic_id = tr.topic_id
LEFT JOIN topicwatchdog.transcripts_cleaned tc ON vt.video_youtube_id = tc.video_youtube_id
LEFT JOIN topicwatchdog.dim_videos dv ON dv.video_youtube_id = vt.video_youtube_id
WHERE topic_label IS NULL OR topic_label = ''
GROUP BY vt.topic_id;
-- store the prompts by using these examples
CREATE TEMP TABLE _prompts AS
SELECT
topic_id,
(
'Du bist politischer Analyst. Vergib einen prägnanten, verständlichen ' ||
'Titel (max. 120 Zeichen) für diesen **politischen Anspruch/Behauptung**-Cluster. ' ||
'Regeln: deutsch, neutral, keine neuen Themen/Namen erfinden, ' ||
'nur EIN kurzer Titel. Antworte strikt Text ohne Markdown oder json. ' ||
'\n\nBeispiele (Original-Canonicals):\n' ||
STRING_AGG('- ' || ex, '\n')
) AS prompt
FROM _cluster_examples, UNNEST(examples) AS ex
GROUP BY topic_id;
-- get all the topic_label entries for topic_id by executing the prompts
CREATE TEMP TABLE _raw_llm AS
SELECT
topic_id,
ml_generate_text_llm_result AS topic_label
FROM ML.GENERATE_TEXT(
MODEL `topicwatchdog.gemini_remote`,
TABLE _prompts,
STRUCT(
TRUE AS flatten_json_output,
0.2 AS temperature,
1024 AS max_output_tokens
)
) AS gen;
-- store them into the topic_registry as new topic_label
MERGE `topicwatchdog.topic_registry` dst
USING (
SELECT topic_id, topic_label
FROM _raw_llm
WHERE topic_label IS NOT NULL
) src
ON dst.topic_id = src.topic_id
WHEN MATCHED THEN
UPDATE SET dst.topic_label = src.topic_labelResult:
We now have a persistent table topic_registry mapping numeric cluster IDs → stable human-readable names like:
| topic_id | cluster_label |
| -------- | ---------------------------------------------------------- |
| 1 | Politische Abgrenzung und Ablehnung |
| 2 | Abgrenzung und Ablehnung politischer Strömungen |
| … | … |
This makes Looker Studio dashboards far easier to interpret.
9) Results & Charts
With BERTopic wired into the pipeline, I can finally see stable topics across multiple days.
In Looker Studio I built one new view only for the BERTopic data:
-
BERTopic A daily histogram of processed videos, a topic list with top channels per topic, and a topic share pie chart.
Finally a list of all videos matching the result and a possibility to select the timerange.
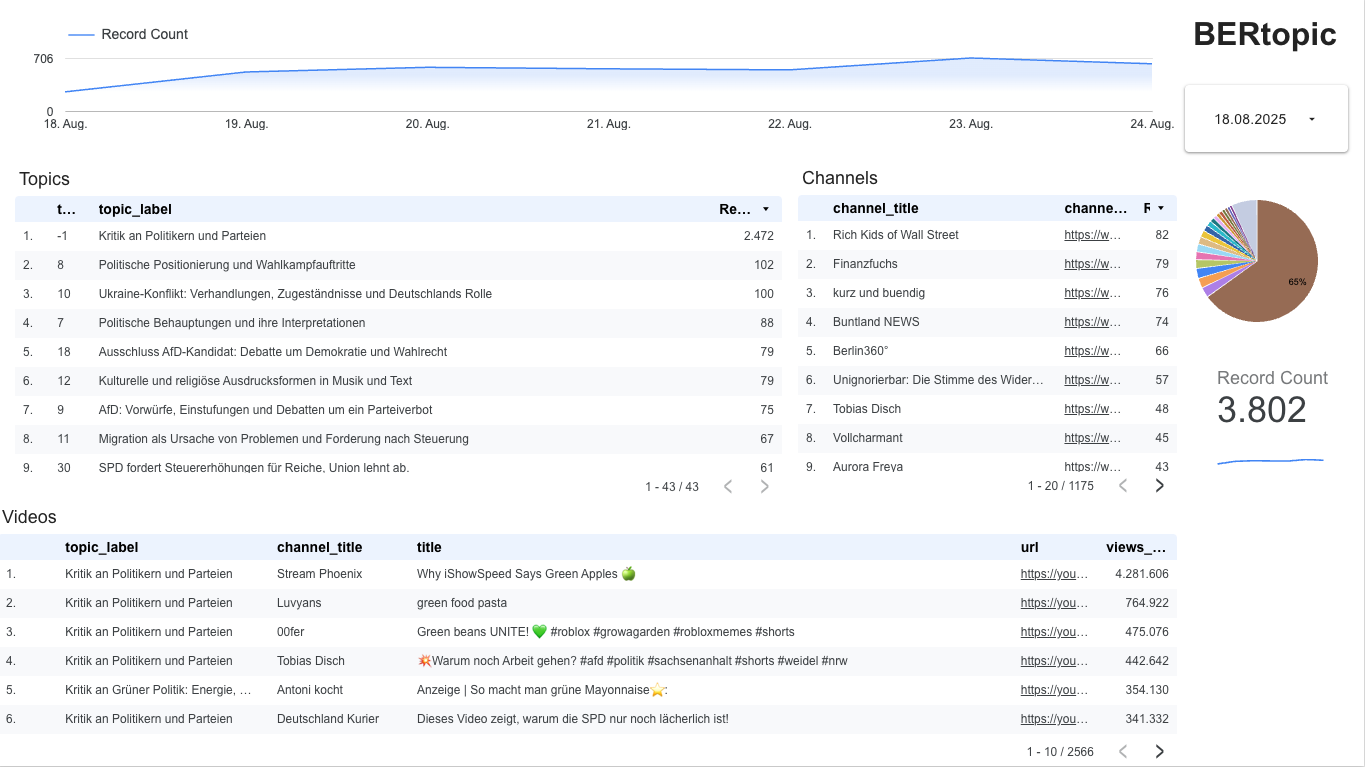
As you can see the Kritik an Politikern und Parteien has the topic_id equal -1, which means it is not properly assigned to a topic. Even though 2472 are mapped to -1 it still looks good for the rest of the 3802.
10) Limitations & Next Steps
While BERTopic + registry mapping solves the ID-stability problem, some challenges remain:
-
Registry growth
Every new internal BERTopic cluster gets a new stable ID. Over time, the registry may bloat with near-duplicates. -
Outliers
BERTopic assigns many snippets to-1. These are tracked but need strategies, e.g., (a) filter-1, (b) lowermin_cluster_size, (c) periodic retrain on outliers only. -
Compute cost
Python BERTopic requires embeddings outside BigQuery ML. I need to benchmark cost and latency vs. the in-BQ approach.
Next steps:
- Build a review UI in PayloadCMS to merge/split/rename stable topics.
- Add execution & ops tracking to run it more regularly.
- Start including claims and define how to model them (IDs, relations, stability).
This closes Week-3: we now have stable, versioned Topic IDs — a foundation for true longitudinal analysis.



