This post documents Week 1 of a research project I call TopicWatchdog: an end‑to‑end, reproducible pipeline that (a) collects German political short videos, (b) transcribes them, (c) extracts topics and claims with timestamps, and (d) persists everything in BigQuery for transparent, long‑term analysis.
The focus is on methods and reproducibility, not on polished production code. The snippets below are meant as guidance scaffolding, but already allow you to build a similar pipeline.
Table of Contents
- Research Scope & Data Ethics
- GCP Setup (Projects, Service Accounts, Pub/Sub, Cloud Run)
- Data Model (BigQuery schemas + partitioning/cluster strategy)
- YouTube Ingestion (crawler job)
- Transcription (captions first, STT fallback)
- LLM Extraction (topics & claims) with structured output
- Week‑1 Looker Studio views (3 charts + SQL views)
- Limitations (Week 1) & Next Steps
1) Research Scope & Data Ethics
- Scope: Public, short German‑language political videos. No private data, no face recognition.
- Goal: Quantify what is talked about (topics/ressorts) and what is asserted (claims) over time.
- Ethics: Minimize model bias (document model/version/parameters), keep audit trails, publish methodology, allow reproducibility.
2) GCP Setup (Projects, Service Accounts, Pub/Sub, Cloud Run)
Because I wanted to host it with minimal cost using cloud-native infrastructure (and since I am Google Cloud certified), I created a new project and a BigQuery dataset called topicwatchdog.
For the important steps it was clear, that we need cloud run jobs
collect-youtube-videos
and some cloud run services
transcribe-videosextract-topicsextract-claimspayload
and a cloud pubsub for each to message them.
Since I like to use payload as CMS, I used also the new mongodb compatibility for firestore to see if it works for my usecase (pretty much free - depending on the amount of data).
The data can be visualized in looker studio afterwards.
3) Data Model (BigQuery)
The data exists in the selfhosted payload, but for BigQuery ML and such things, I need it also in in BigQuery. The structure there is pretty straight forward for my use case and needs a table for dim_channels and dim_videos to have the details about the found channels and videos.
CREATE TABLE IF NOT EXISTS `topicwatchdog.dim_channels` (
channel_youtube_id STRING NOT NULL,
title STRING,
published_at TIMESTAMP
)
PARTITION BY DATE(published_at)
CLUSTER BY channel_youtube_id;
CREATE TABLE IF NOT EXISTS `topicwatchdog.dim_videos` (
video_youtube_id STRING NOT NULL,
channel_youtube_id STRING NOT NULL,
title STRING,
published_at TIMESTAMP
)
PARTITION BY DATE(published_at)
CLUSTER BY video_youtube_id;On the other hand I want to store the extracted topics and claims, thus I needed also the table for fact_topics and fact_claims.
CREATE TABLE IF NOT EXISTS `topicwatchdog.fact_topics` (
video_youtube_id STRING NOT NULL,
topic STRING,
parent STRING,
canonical STRING,
description STRING,
ressort STRING,
action STRING,
target STRING,
intensity STRING,
stance STRING,
confidence FLOAT64,
topic_timestamp TIMESTAMP
)
PARTITION BY DATE(topic_timestamp)
CLUSTER BY topic, video_youtube_id;
CREATE TABLE IF NOT EXISTS `topicwatchdog.fact_claims` (
video_youtube_id STRING NOT NULL,
claim STRING,
parent STRING,
canonical STRING,
description STRING,
action STRING,
target STRING,
intensity STRING,
stance STRING,
confidence FLOAT64,
claim_timestamp TIMESTAMP
)
PARTITION BY DATE(claim_timestamp)
CLUSTER BY video_youtube_id, claim;4) Collect Daily Videos
Approach: pull daily by search terms + time window; store video metadata in dim_videos; publish transcription tasks to Pub/Sub.
There are some guardrails for this: A youtube api key allows only usage of 10000 units per day. The search query takes 100 units (for 50 results), a video list 1 unit (for 50 ids) and a channel list 1 unit (for 50 ids).
This means I can only perform a limited number of fetches per day before hitting the quota limits — but for my research that is sufficient.
Since I knew that specific partys in germany use hashtags like #spd, #cdu, #grüne, #fdp, #csu, #afd, #bsw the approach looks in node.js like this:
const SEARCH_TERMS = ['cdu', 'spd', 'afd', 'grüne', 'bsw', 'csu', 'fdp']
for (const term of SEARCH_TERMS) {
try {
const newIds = await processSearchTerm(term, MAX_RESULTS)
console.log(`✅ ${newIds.length} new videos stored for "${term}"`)
} catch (err) {
console.error(`❌ Error for term "${term}":`, err)
}
}which worked pretty well. The processSearchTerm is a bit more complicated and initially searches for all relevant videos of the current day
import { google } from 'googleapis';
const youtube = google.youtube('v3');
const searchResponse = await youtube.search.list({
key: YOUTUBE_API_KEY,
part: 'snippet',
q: term,
maxResults,
publishedAfter,
publishedBefore,
relevanceLanguage: 'de',
videoDuration: 'short',
type: 'video',
order: 'viewCount',
pageToken: nextPageToken || null,
})and uses all channelIds and videoIds found in it to do:
const videosResponse = await youtube.videos.list({
key: YOUTUBE_API_KEY,
part: 'snippet,statistics,contentDetails',
id: videoIds.join(','),
})
const channelResponse = await youtube.channels.list({
key: YOUTUBE_API_KEY,
part: 'snippet,statistics',
id: channelIds.join(','),
})Based on this data I could form a full entity (for payload) of the video, which looks like this:
const body = {
youtubeId: video.id,
title: snippet.title,
description: snippet.description,
publishedAt: snippet.publishedAt,
channelId: snippet.channelId,
channelTitle: snippet.channelTitle,
thumbnails: snippet.thumbnails,
defaultLanguage: snippet.defaultLanguage,
viewCount: parseInt(statistics.viewCount || '0', 10),
channel: savedChannel.id,
isTranscriptExtractionTriggered: true,
etag: video.etag,
contentDetails: {
duration: youtubeDurationToSeconds(contentDetails?.duration),
caption: contentDetails?.caption,
},
statistics: {
viewCount: parseInt(statistics?.viewCount || '0', 10),
likeCount: parseInt(statistics?.likeCount || '0', 10),
favoriteCount: parseInt(statistics?.favoriteCount || '0', 10),
commentCount: parseInt(statistics?.commentCount || '0', 10),
},
}the youtube.search.list does not allow parts like statistics,contentDetails and snippet's version of description is truncated - thus the extra call is necessary.
The final video for each of them get's pushed like this to payload:
const res = await fetch(`${PAYLOAD_API_URL}/api/videos`, {
method: 'POST',
headers: {
Authorization: `third-party-access API-Key ${PAYLOAD_API_SECRET}`,
'Content-Type': 'application/json',
},
body: JSON.stringify(body),
})Finally the newly submitted video (via payload hook CollectionAfterChangeHook pushes to pubSub like this:
import { PubSub } from '@google-cloud/pubsub'
const pubSubClient = new PubSub({
scopes: ['https://www.googleapis.com/auth/cloud-platform'],
})
const messageId = await pubSubClient.topic('transcript-extraction-topic').publish(
Buffer.from(
JSON.stringify({
kind: 'extractTranscript',
messageTopicName: 'payload-messages',
youtubeId: doc.youtubeId,
}),
),
)I reference the payload-messages topic to make sure that payload receives the result of this async process later.
5) Transcription
To extract what people have been saying in the given videos, I wanted to know how to get this data. I wanted to build transcribe-videos for this.
YouTube often provides captions, which at first glance seemed like a perfect fit. But the problem is that there is no official api (for public data). There is an api to fetch the transcriptions for your own videos, but not for publically posted ones.
To test my approach personally I downloaded some transcripts of the videos manually and pushed it to payloadcms in the "transcript" text field. That's enough to continue but for an overall pipeline it's definately a blocker.
If this part would work, it would publish the transcriptExtracted message to the payload pubsub messages and payload persists the finished transcription to the payload entity.
The transcript would look like this (for a video which discusses if the earth is flat in german at https://www.youtube.com/watch?v=gyal9T_fQ-8):
00:00 In unserer Reihe
'Große Überraschung aus der Wissenschaft'...
00:04 jetzt die allerneueste Überraschung.
00:07 Nicht nur der Bildschirm ist flach.
00:09 Die Erde ist es auch.
00:11 *Vorspann*
00:18 Es hat sich jetzt gezeigt...
00:20 die Erde ist eine Scheibe.
00:23 Ringsum die Erde befindet sich die Antarktis.
...6) LLM Extraction (topics & claims) — structured output
Goal: Deterministic JSON suitable for BQ ingestion. Keep prompts versioned.
I was not quite sure how suitable it is (spoiler: not really!), but it looked very promising thus I will share it here.
I took the transcript like mentioned earlier and I used the following prompt with gemini-2.5-flash-lite:
Du bist ein neutraler politischer Analyst.
Ich gebe dir ein Transkript eines politischen Gesprächs oder Statements, bei dem jede Zeile mit einem Zeitstempel beginnt (z. B. 00:01: Text…).
Deine Aufgabe ist es, die besprochenen Themen klar zu extrahieren und den Themen jeweils zuzuordnen, ob in welches politisches Ressort sie gehören.
Für jedes Topic liefere:
1) topic: kurze Originalbezeichnung des Topics in den Worten des Sprechers (falls mehrere Varianten, die häufigste/typischste Formulierung),
2) description: 1–2 Sätze, die den Inhalt des Topics im Kontext des Videos knapp und neutral zusammenfassen,
3) ressort: übergeordnetes Politikfeld (z. B. "Migration", "Wirtschaft", "Energie", "Sicherheit", "Demokratie", "Bildung", "Gesundheit", "Außenpolitik", "Soziales", "Digitales", "Verkehr", "Klima/Umwelt"). Wähle die beste passende Kategorie.
4) action: die zentrale Maßnahme/Handlung (Verb- oder Nominalform), z. B. "Grenzschutz verschärfen", "Strompreis deckeln".
5) target: primäres Ziel/Objekt der Maßnahme, z. B. "illegale Einreisen", "Haushalte", "Unternehmen".
6) intensity: {low|medium|high}, geschätzt aus Betonung/Dringlichkeit/Absolutheitsgraden.
7) stance: {pro|contra|neutral} relativ zum beschriebenen Topic.
8) canonical: kanonische, neutrale Kurzform (max. 7 Wörter) des Topics, die sinngleiche Formulierungen vereinheitlicht. Keine Parolen, keine Eigennamen; möglichst generisch.
9) parent: kanonische, neutrale Kurzform (max. 7 Wörter) des Überbegriffs des Topics, die sinngleiche Formulierungen vereinheitlicht. Keine Parolen, keine Eigennamen; möglichst generisch.
10) mentions: Liste aller Textstellen im Format:
[{ "timestamp": <sekunden_als_integer>, "excerpt": "<max 20 wörter originalzitat>" }]
- Fasse unmittelbar aufeinanderfolgende oder stark überlappende Stellen zusammen.
11) confidence: Zahl 0–1, wie sicher du bist, dass das Topic korrekt erkannt und strukturiert ist.
Regeln: - Sei neutral, keine Wertung. - Keine Halluzinationen: Stütze dich nur auf Aussagen im Transkript. - Nutze description_raw als kurze, informative Zusammenfassung (kein Slogan). - canonical muss prägnant und stabil sein (geeignet für GROUP BY). - Gib nur valides JSON gemäß dem Feld "response" zurück.
Gib das Ergebnis in folgender Struktur zurück:
json [ { "topic": "Energiepreise senken", "description": "Vorschläge zur Entlastung privater Haushalte, insbesondere durch einen Strompreisdeckel.", "ressort": "Wirtschaft", "action": "Strompreis deckeln", "target": "Haushalte", "intensity": "mittel", "stance": "pro" "canonical": "Energiepreise für Haushalte senken", "mentions": [ { "timestamp": 12, "excerpt": "Energiepreise für Haushalte senken" }, { "timestamp": 20, "excerpt": "Strompreisdeckel würde Familien entlasten" } ], "confidence": 0.86 }, { "topic": "Strengerer Grenzschutz und Rückführungen", "description": "Forderungen nach konsequenteren Grenzkontrollen und beschleunigten Rückführungen.", "ressort": "Migration", "action": "Grenzschutz verschärfen", "target": "illegale Einreisen", "intensity": "hoch", "stance": "pro" "canonical": "Grenzschutz & Rückführungen verschärfen", "mentions": [ { "timestamp": 65, "excerpt": "konsequentere Kontrollen beim Grenzschutz" }, { "timestamp": 72, "excerpt": "Rückführungen müssen schneller erfolgen" } ], "confidence": 0.88 } ]
Wenn du dir nicht sicher bist, antworte mit einem leeren JSON-Array [].
Gib ausschließlich plain JSON zurück, ohne '```json' Kommentar oder Markdown.
Hier ist das Transkript (mit Zeitstempeln "MM:SS: Text" bzw. "HH:MM:SS: Text"):
and executed it with structured json response like this:
const { GoogleGenAI, Type } = require('@google/genai')
const ai = new GoogleGenAI({
vertexai: true,
project: process.env.GOOGLE_CLOUD_PROJECT,
location: process.env.GOOGLE_CLOUD_LOCATION,
})
const response = await ai.models.generateContent({
model: MODEL_NAME,
contents: `${prompt}\n\n${transcript}`,
config: {
responseMimeType: 'application/json',
temperature: 0.2,
responseSchema: {
type: Type.ARRAY,
items: {
type: Type.OBJECT,
properties: {
topic: { type: Type.STRING },
description: { type: Type.STRING },
ressort: { type: Type.STRING },
action: { type: Type.STRING },
target: { type: Type.STRING },
intensity: { type: Type.STRING, enum: ['low', 'medium', 'high'] },
stance: { type: Type.STRING, enum: ['pro', 'contra', 'neutral'] },
canonical: { type: Type.STRING },
parent: { type: Type.STRING },
confidence: { type: Type.NUMBER },
mentions: {
type: Type.ARRAY,
items: {
type: Type.OBJECT,
properties: {
timestamp: { type: Type.NUMBER },
excerpt: { type: Type.STRING },
},
propertyOrdering: ['timestamp', 'excerpt'],
},
},
},
required: [
'topic',
'description',
'ressort',
'confidence',
'mentions',
'canonical',
'parent',
'action',
'target',
'intensity',
'stance',
],
propertyOrdering: [
'topic',
'description',
'ressort',
'canonical',
'confidence',
'parent',
'action',
'target',
'intensity',
'stance',
'mentions',
],
},
},
},
})this gave me a promising result for the flat earth video like this:
[
{
"topic": "Erde ist eine Scheibe",
"description": "Diskussion über die Hypothese, dass die Erde flach ist und von einem Eiswall umgeben wird, im Gegensatz zur wissenschaftlichen Erkenntnis einer kugelförmigen Erde.",
"ressort": "Wissenschaft",
"canonical": "Flache Erde Hypothese",
"parent": "Wissenschaft",
"action": "Diskutieren",
"target": "Erde",
"intensity": "low",
"stance": "contra",
"mentions": [
{
"timestamp": 20,
"excerpt": "die Erde ist eine Scheibe."
},
{
"timestamp": 23,
"excerpt": "Ringsum die Erde befindet sich die Antarktis."
},
{
"timestamp": 43,
"excerpt": "Das Wasser fließt also eben nicht von der Scheibe runter"
},
{
"timestamp": 123,
"excerpt": "Die Erde sei flach"
},
{
"timestamp": 330,
"excerpt": "wenn die Erde eine Scheibe ist"
},
{
"timestamp": 445,
"excerpt": "Wie soll aus einem unförmigen Klumpen aus irgendwelchem Material eine Scheibe werden?"
},
{
"timestamp": 634,
"excerpt": "viel dran sein, kann doch an einer Flacherde nicht."
},
{
"timestamp": 65,
"excerpt": "die Erde ist eine Scheibe."
}
]
}I used a similiar approach to extract the claims made by the video and the result looked like this:
[
{
"claim": "Die Erde ist eine Scheibe mit der Antarktis als Eiswall ringsum.",
"description": "Es wird die Hypothese vertreten, dass die Erde eine Scheibe sei und die Antarktis als Eiswall die Ozeane umschließe, damit das Wasser nicht abfließe.",
"ressort": "Wissenschaft",
"canonical": "Erde ist eine Scheibe mit Antarktis als Eiswall",
"parent": "Erde",
"action": "Erde ist Scheibe",
"target": "Erde",
"intensity": "low",
"stance": "neutral",
"excerpts": [
{
"timestamp": "00:20",
"excerpt": "die Erde ist eine Scheibe."
},
{
"timestamp": "00:23",
"excerpt": "Ringsum die Erde befindet sich die Antarktis."
},
{
"timestamp": "00:38",
"excerpt": "Dieser Eisrand hält nun eben die Ozeane zusammen wie ein großes Waschbecken."
}
]
}
]7) Week‑1 Looker Studio Views & Charts
I took 175 videos and their transcripts and executed the process. As you can see my prompts already included canonical or parent topics and ressorts to make it possible to cluster them - but it looks like the approach does not properly work. We will explore this next week.
So for topics (extracted 295 in total) I received these charts for topics, which looked quite good:
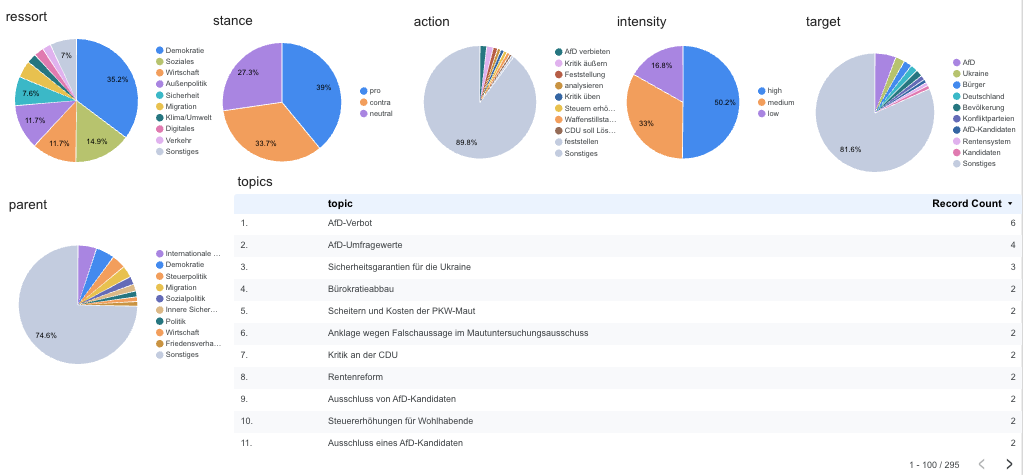
However, this revealed a major limitation: topics often appeared under slightly different names, which prevented effective clustering so far.
The claims (extracted 244 in total) suffered similiarly:
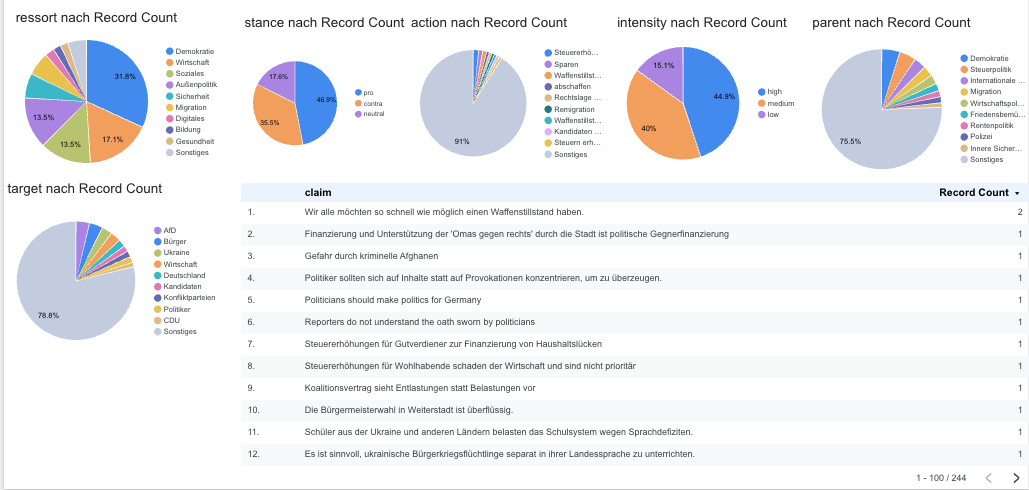
8) Limitations (Week 1) & Next Steps
Limitations: small sample size (≈175 videos), no stable Topic IDs yet, clustering not applied, and claims only minimally canonicalized.
Next:
- Stable Topic IDs via canonicalization & ID function; versioned labels.
- Embedding‑based clustering (BERTopic/HDBSCAN) + canonical labels.
- Drift/Bias monitoring & a lightweight human‑in‑the‑loop review UI.
I will keep you posted!



